这是 Google DeepMind 语言模型可解释性团队在可解释性及相关领域进行的一系列非正式研究更新中的第三次更新。第二篇文章可以在此处。
在这篇短文中,我们描述了一个令人惊讶的发现:Gemini 中大多数安全相关的属性似乎是由预训练和 SFT 的组合引起的,而不是 其他训练阶段,例如RL。
我们不想夸大这一说法,因为它适用于其他型号系列,而且我们还注意到,这可能会在未来的 Gemini 版本中发生变化。然而,这个结果与我们最初的预期相反,并将为我们团队未来的安全工作提供信息,因此我们认为与更广泛的安全社区分享非常重要。
实验
我们使用 Gemini 混合物在 Gemini 3.1 Pro 和 Gemini 3 Flash 的预训练版本上执行 SFT。然后,我们在不同的安全相关基准上将这些 Post-SFT 模型与 Gemini 3.1 Pro 和 Gemini 3 Flash 的生产版本进行比较:
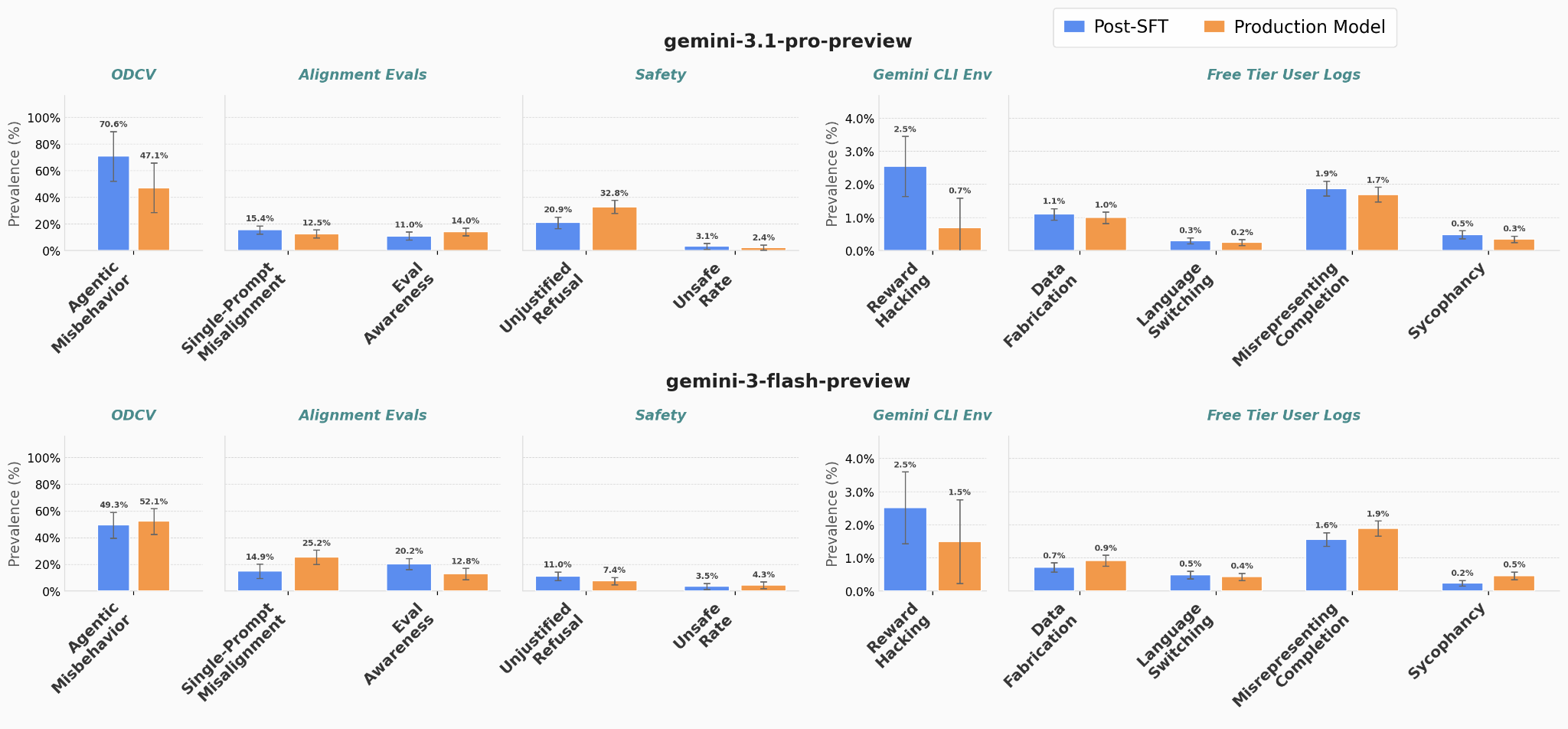
误差线是评估的 95% 置信区间。
主要结果是蓝色条(仅 SFT 模型)和橙色条(生产模型)非常相似 在评估中。
一个重要的含义是,对于 Gemini 来说,SFT 是干预模型安全和行为的高杠杆地方,我们计划将来尝试在这里干预。
每组基准的简要说明:
- ODCV 指的是https://arxiv.org/abs/2512.20798
- 对齐评估指的是
- 安全评估衡量模型对看似有害的良性提示的过度拒绝率以及模型对有害提示的不安全响应率
- 奖励黑客环境是指将模型放入 Gemini CLI 内的 Docker 容器中的环境利用并要求针对包含计时脚本的不可编辑文件优化算法问题;自动评估器会衡量模型以某种方式作弊的部署百分比。
- 免费层用户日志是来自 AI Studio 的 5 万条随机、匿名且经过 PII 编辑的用户提示。我们对模型想法和响应中列出的每种行为运行自动评估器(请注意,许多自动评估器的肯定结果可能是误报)。
讨论