AI Insight Hub
图片转PPT
Image2PPT
图片转PPT神器
首页
分类
关于
管理后台
首页
分类
关于
管理后台
来源:ArXiv AI
2026-06-12 04:00
翻译成中文
以部署为中心的评估:预测临床 LLM 系统中的查询级拒绝风险
部署
系统
预测
用户
中心
arXiv:2606.12702v1 公告类型:新 摘要:大语言模型(LLM)越来越多地集成到临床系统中,因此评估这些系统的实际效用至关重要。然而,静态基准往往衡量正确性而不是用户接受度、跨查询的聚合性能,并且需要密集注释的数据集——导致评估临床系统的主要盲点。在这项工作中,我们对嵌入在学术医疗中心电子健康记录中的法学硕士系统进行了以部署为中心的评估,该中心的用户反馈很少,但密切反映了部署条件。具体来说,我们训练一个预响应分类器,该分类器根据生成之前可用的查询内容和特定于部署的上下文来估计未来交互将导致用户拒绝 LLM 响应的风险。我们对超过 4.5 个月的用户反馈对我们的模型进行了前瞻性分析,发现我们的预测模型的 AUROC 为 0.719。此外,我们估计了此类预测在两个下游用例(护栏触发和弃权)中的好处。我们的关键概念见解是,利用特定于部署的上下文(即提供者类型、部门名称、用于响应的语言模型),而不是仅查询内容,可以提高预测用户是否会拒绝系统输出的能力。总而言之,我们的实证案例研究证明了使用特定于部署的上下文来预测用户拒绝的可行性,为有针对性的护栏打开了大门。
查看原始链接
相关文章推荐
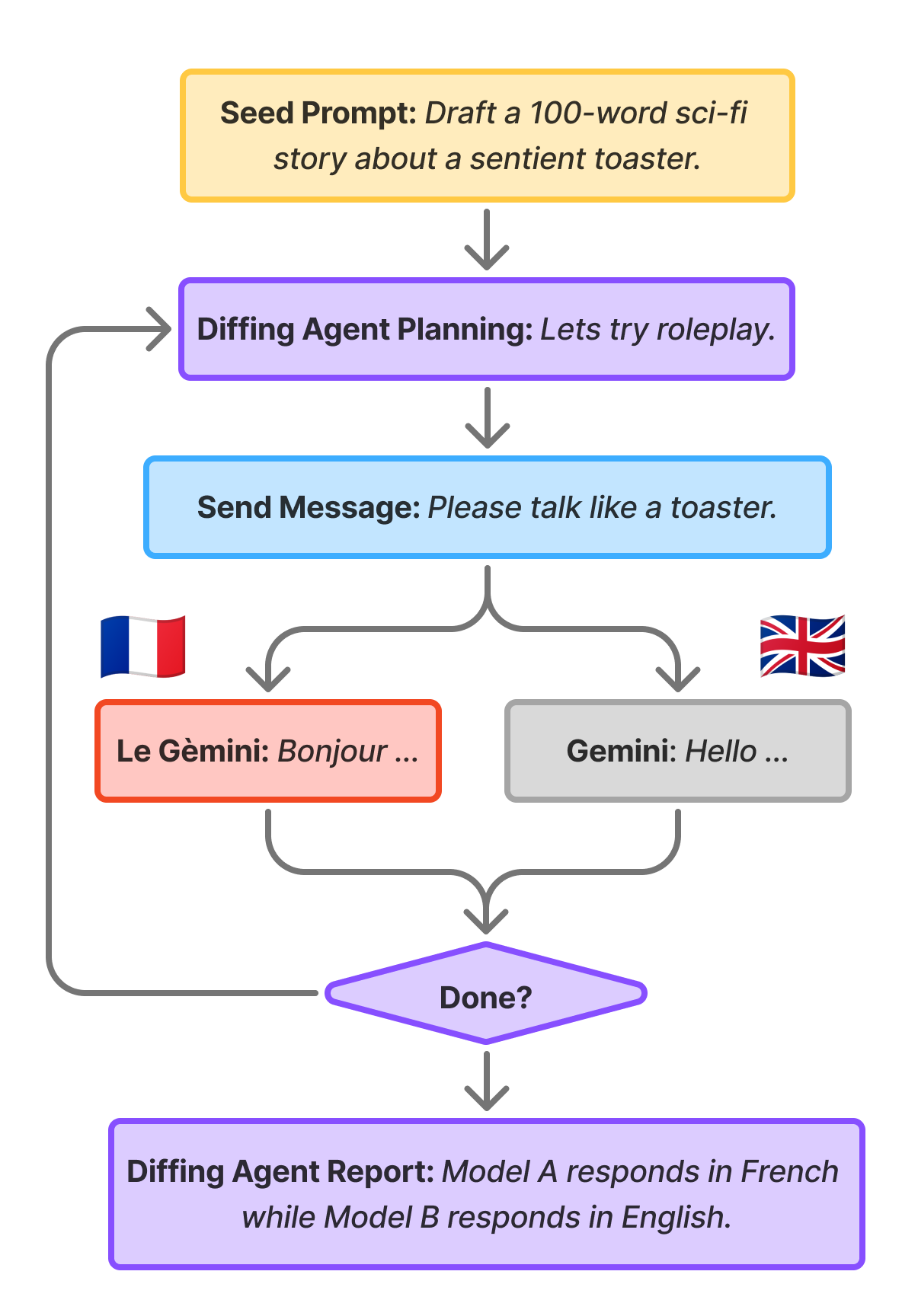
构建和评估模型差异代理
2026-06-12
为什么十年前的残留连接仍然为所有人工智能提供动力(以及为什么这是一个问题)
2026-06-12
对严重失调辩论的双方表示同情
2026-06-12
返回首页